
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
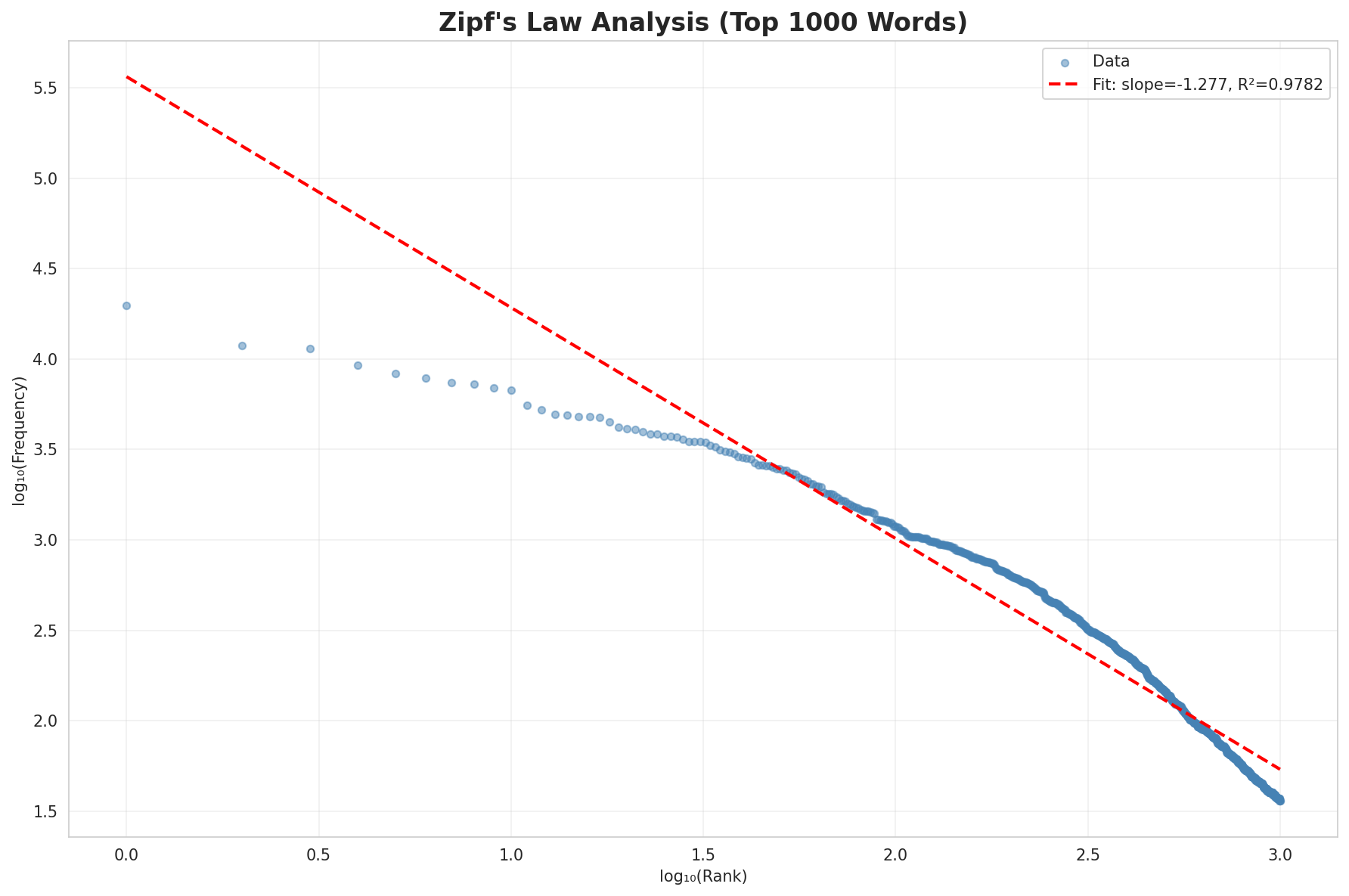
- Xet hash:
- 6771130a0422314780f4d557e5d2facca6a5697351aaa1a0628c372fbb691d32
- Size of remote file:
- 104 kB
- SHA256:
- c44ac149f3511aa24299788d1c524eea04bbf63f8dd3c5976f4c94ca76d72d10
·
Xet efficiently stores Large Files inside Git, intelligently splitting files into unique chunks and accelerating uploads and downloads. More info.