
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
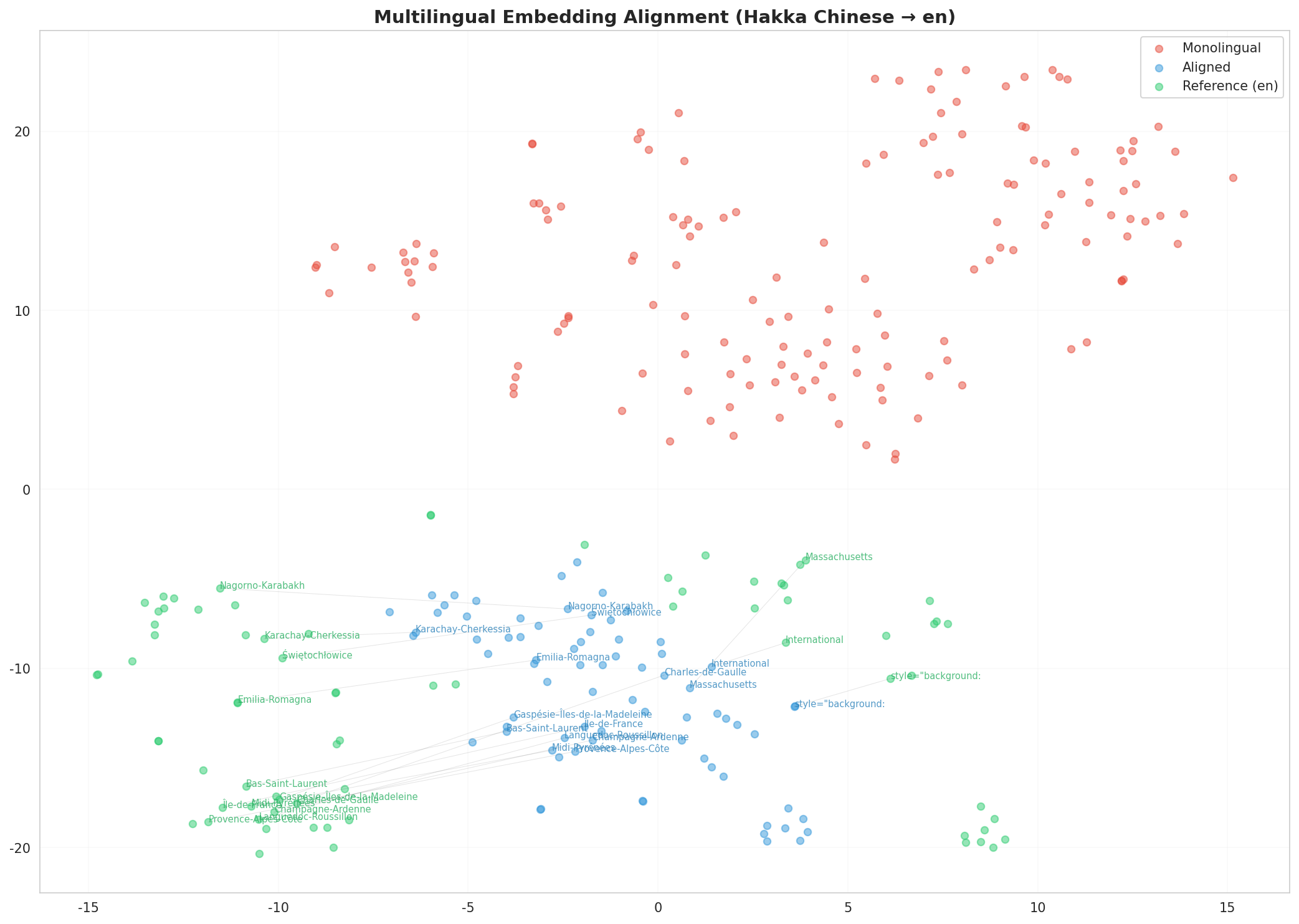
- Xet hash:
- 03e49ee6ee28b7ea857ded61a32cae829034583ded669b958035b1c90b28920f
- Size of remote file:
- 231 kB
- SHA256:
- 1fdd588ddb1b297648d37a8c758c62f71afc9caeb52ef7a8dc26a75eca3b40cb
·
Xet efficiently stores Large Files inside Git, intelligently splitting files into unique chunks and accelerating uploads and downloads. More info.